Este es otro de los modelos contrario al modelo Binomial. Si en este los resultados del experimento son independientes uno de otro, en el caso de una Distribución Hipergeométrica los resultados siguientes dependen de los anteriores. Esto ocurre ya que el experimento o fenómeno se realiza sin reposición. Por esta razón, la variable aleatoria definida como el número de éxitos obtenidos tiene una distribución Hipergeométrica.
Definición
Suponga que una cierta población de tamaño N, contiene m elementos que poseen determinado atributo o característica. Suponga también que de esta población se desea extraer sin reposiciónĀ una muestra de n elementos y estamos interesados en saber el número de elementos en la muestra que poseen dicho atributo o característica. Si definimos a X como el número de elementos con dicho atributo, la probabilidad de obtener éxito (que posea dicho atributo) en la primera será m/N, la probabilidad de que el segundo también sea éxito será (m-1)/(N-1) y de que lo sea sabiendo que el primero no lo fue, será m/(N-1).
ĀSi ahora se elige una muestra de tamaño n la variable X así definida tendrá Distribución Hipergeométrica con parámetros N, m, n; es decir H(N, m, n) cuya función de probabilidad viene dada por
Ā 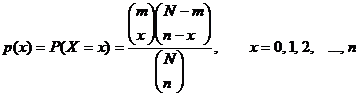
Observaciones:
Hipergeométrica con Minitab
Como en el caso de la Binomial, aquí también la Distribución Hipergeométrica se encuentra como opción dentro de <Probability Distribution> del comando <Calc>.
La siguiente figura muestra la ventana que se obtiene después de ejecutar esta secuencia.
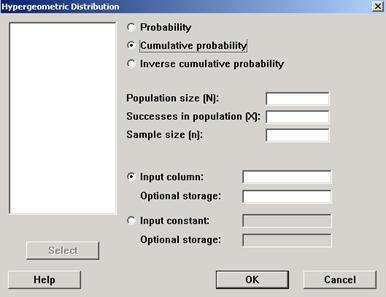 |
Seleccionar <Probability> si desea una distribución de la función de densidad
Seleccionar <Cumulative probability> si desea trabajar con la función acumulativa
Como en el caso de la binomial, se seleccionará <Inverse cumulative probability> si desea obtener un valor particular de X para el cual se conoce su probabilidad acumulada.
A continuación se debe ingresar:
El tamaño de la población, N;
En <Successes in population> ingresar el valor de r; aquellos que poseen un cierto atributo;
En <Sample size (n)> Ingresar el tamaño de la muestra, n;
Si se desea obtener la distribución de X:
En <Input column> ingresar la columna donde se encuentran los valores de X
En <Optional storage> ingresar la columna donde desea almacenar la distribución
En <Input constant> ingresar valor de X, digamos c, para el cual se quiere obtener la probabilidad individual, P(X = c) o la acumulada P(X Ż c).
Puesto que todos los problemas de variable con distribución hipergeométrica son similares, desarrollaremos sólo un ejemplo para ilustrar el uso del Minitab en su solución.



© Ilmer Condor Espinoza. Todos los derechos reservados.
Prohibida la reproducción por cualquier medio.
Publicación web autorizada a aulaClic.
Enero-2009.
Síguenos en: Facebook Sobre aulaClic Política de Cookies