Muchas veces cuando se realizan estudios de muestreo comparando promedios, se extraen muestras de la misma población, y el tratamiento al que se les somete es el mismo que se les da a los que provienen de diferente población. Sin embargo hay situaciones en los que el experimento consiste en evaluar el rendimiento de los elementos de una muestra bajo dos circunstancias diferentes. Por ejemplo, cuando a una muestra de n pacientes se les evalúa su nivel de colesterol antes de aplicarles algún medicamento y luego se vuelve a evaluarlos después de la aplicación del medicamento. Otro ejemplo: A un grupo de trabajadores de una empresa se les somete a dos métodos de capacitación para medir la eficacia de los dos métodos. En ambos ejemplos se trata de la misma muestra. Cada elemento de esta muestra genera dos resultados Xi e Yi. Se trata de probar si el rendimiento promedio de ambos tratamientos es la misma o medir su eficacia. Este tipo de problema es lo que constituye problemas de datos pareados y para el cual se puede realizar procesos de estimación por intervalos o formular hipótesis a fin de verificar los resultados.
Definición
Sea X1, X2, ..., Xn los resultados obtenidos en una muestra de tamaño n, al evaluar sus elementos bajo alguna forma de experimento. Sea Y1, Y2, ..., Yn los resultados obtenidos luego de aplicar algún tratamiento a la misma muestra. Y supongamos que esta muestra ha sido extraída una población N(m2 , s2˛).
Sea (X, Y) una variable aleatoria muestral cuyos elementos se definen como pares ordenados de la forma (X1, Y1), (X2, Y2), ...., (Xn, Yn). Estas variables no son independientes. Veamos por qué: Si Xi representa el nivel de colesterol que tiene el i-ésimo paciente antes de suministrarle un medicamento, Yi representa el nivel de colesterol del mismo paciente después de suministrarle dicho medicamento, sin duda, los resultados probablemente sean diferentes.
Si definimos a D como función de dos variables aleatorias D = X – Y, entonces D es una variable aleatoria poblacional, cuyos parámetros son
mD = E(D) = E(X – Y ) = mX - mY
sD˛ = V(D) = V(X–Y) = V(X) + V(Y) – 2Cov(X, Y) = s1˛ + s2˛ - 2Cov(X,Y)
donde Cov(X, Y) = E(XY) – E(X)E(Y) = mXY - mX mY
De manera que si en una muestra aleatoria de
tamaño n, definimos el estadístico ![]() , cuya
media y varianza muestral son
, cuya
media y varianza muestral son
![]() y
y
![]()
entonces su distribución de probabilidad viene dada por
![]()
![]()
Y puesto que la población de donde provienen
es normal, por la Propiedad Reproductiva de la Normal, ![]()
Para la estimación del Intervalo de Confianza y una Prueba de Hipótesis, debemos contemplar dos casos:
Caso I: Cuando el tamaño de la muestra es suficientemente grande (n ł 30)
Por el TLC usamos 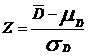 tal que Z ŕ N(0, 1)
tal que Z ŕ N(0, 1)
Caso II: Cuando el tamaño de la muestra es pequeño (n < 30)
En este caso usamos la distribución t de Student calculando
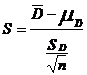 tal
que S ŕ t(n-1)
tal
que S ŕ t(n-1)
El intervalo de confianza de (1 - a )x100% y los tres tipos de Prueba de Hipótesis se realizan utilizando el mismo procedimiento dado para la diferencia de medias muestrales.



© Ilmer Condor Espinoza. Todos los derechos reservados.
Prohibida la reproducción por cualquier medio.
Publicación web autorizada a aulaClic.
Enero-2009.
Síguenos en: Facebook Sobre aulaClic Política de Cookies