Por Bloques Completamente Aleatorizado
En este modelo, además de los tratamientos que es un tipo de variable los datos de las muestras de cada tratamiento se agrupan para formar el concepto de FACTOR, el cual a su vez puede ser sometida a un análisis de comparación de los efectos que se encuentren entre los bloques, por ello el modelo en este caso es:
xij = μ + αi + βj + eij, i = 1, 2, …, nj ; j = 1, 2, … k, i = 1, 2, …, l
Frente a este modelo podemos formular las siguientes hipótesis:
Hipótesis de igualdad de medias poblaciones de los tratamientos:
Ho: μ.1 = μ.2 = ⋯ = μ.k = μ
H1: μ.i ≠ μ.j para algún i ≠ j
Hipótesis de igualdad de medias poblacionales por bloque:
Ho: μ1. = μ2. = ⋯ = μl. = μ
H1: μi. ≠ μj. para algún i ≠ j
La deducción de la tabla del ANOVA es similar al modelo anterior, lo cual, en este caso es:
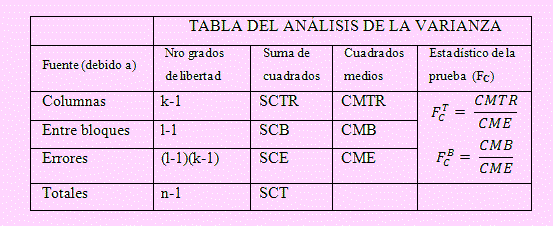
Criterio de decisión para tratamientos:
SiFC >Fα (k-1,n(k-1)(l-1))se rechazará la hipótesis nula.
Criterio de decisión para los bloques:
SiFC > Fα (l-1,(k-1)(l-1)) se rechazará la hipótesis nula.
Ejemplo 02
Una empresa fabricante de componentes para motores diesel debe reemplazar sus máquinas antiguas cuyo costo era bastante oneroso a fin de competir con sus competidores asiáticos. Por esta razón el gerente de producción ordenó someter a estudio cuatro nuevos tipos de máquinas y se probaron por un tiempo encontrándose la producción del número de componentes por hora de cada una de ellas; los datos se muestran en la siguiente tabla:
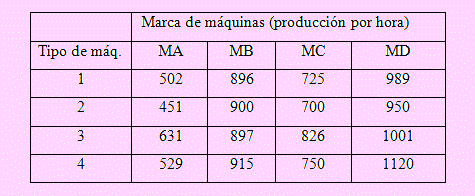
Para tomar una decisión adecuada se planea formular las siguientes hipótesis:
a) No hay diferencia significativa en la producción medias entre las máquinas
Ho: μA = μB = μC = μD
H1: μi ≠ μj para algún i ≠ j
b) No hay diferencia significativa en la producción promedio por tipo de máquina
Ho: μ1 =μ2 = μ3 = μ4
H1: μi ≠ μj para algún i ≠ j Ingresando los datos a otra hoja vacía tendremos
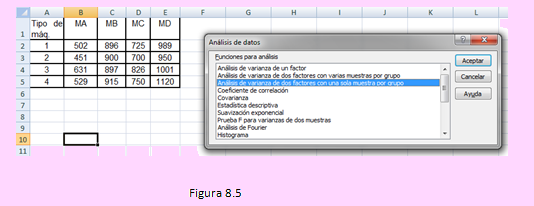
y usando la opción que se indica: Análisis de dos factores con una sola muestra, se tendrá la siguiente ventana de diálogo:
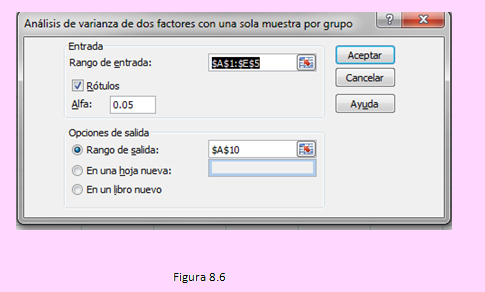
Con lo cual obtendremos la siguiente salida de resultados:
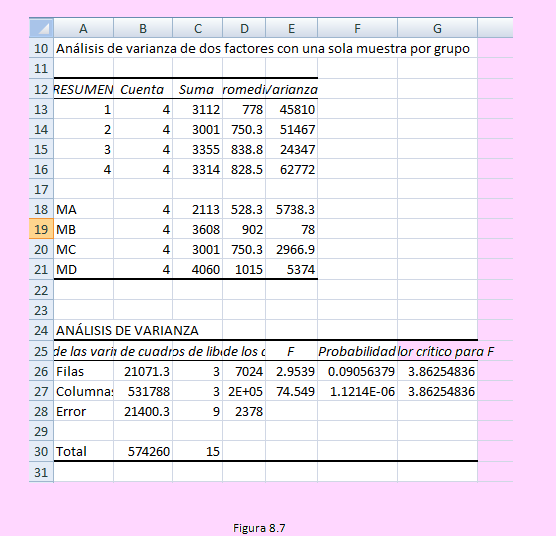
Criterio de decisión:
En el caso de la hipótesis por máquina: Rechazaremos Ho pues el Fc es mayor que el f crítico (74.59 > 3.86254836)
Pero en el caso de la hipótesis por tipo de máquina no se rechaza Ho pues el Fc = 2.9539 no es mayor a el F crítico = 3.86254836
Es decir, la producción promedio de componentes por hora es significativa entre los tipos de máquinas.
Por otro lado, entre las máquinas no hay diferencia significativa en la producción promedio.
Si se decide usando el pValor diríamos: En el caso de las máquinas: Como pValor = 0 < α = 0.05 entonces rechazaremos Ho.
Del mismo modo, en el caso de los bloques: Como pValor = 0.0906 no es menor que α = 0.05 entonces no se rechaza Ho.
Pregunta:
Por qué la respuesta anterior (en cursiva) se expresa como dos respuestas independientes? Se responde si hay diferencia en promedios de producción por máquina y se responde si hay diferencia o no en promedios de producción por tipo de máquina. Y porqué no responde por una ocurrencia simultánea; es decir, que hay una interacción, que hay un evento que ocurre como una interacción entre tratamientos y bloques? Que la variabilidad de los errores se debe a la influencia de las máquinas y los tipos de máquinas?
Esto es lo que pretende el siguiente modelo en el cual tanto a tratamiento como a bloques se les define como dos variables independientes y se trata de encontrar explicación en la interacción entre ellas, además de la influencia entre los tratamientos, entre los bloques y dentro de los tratamientos.



© Ilmer Condor Espinoza. Todos los derechos reservados.
Prohibida la reproducción por cualquier medio.
Publicación web autorizada a aulaClic.
Diciembre -2013.
Síguenos en: Facebook Sobre aulaClic Política de Cookies