Lo dicho en la pregunta anterior nos releva de otros comentarios. A cada variable se la considera como un Factor, uno independiente de otro. A su vez este modelo se divide en dos:
Cuando por cada bloque y por cada tratamiento (una celda) se presenta un solo elemento constituyendo una muestra de tamaño uno.
Y cuando en cada bloque y cada tratamiento se presentan un conjunto de elementos por lo que la muestra tiene un tamaño mayor a uno y en el cual se detecta alguna forma de interacción.
El primero constituye modelo si repetición o sin replicación y el segundo modelo con repetición o con replicación.
Sin Replicación Ahora presentaremos el modelo para formular las hipótesis y pasar a presentar la tabla del análisis de la varianza correspondiente.
Como antes, se X la característica de una población bajo estudio. Un valor de esta variable puede ser expresada como xij que representa el efecto obtenido por la combinación del i-ésimo bloque y el j-ésimo tratamiento.
Por lo que xij = μ + αi + βj + γij + eij, i = 1, 2,…, nj; j = 1, 2,… k, i = 1, 2,…, l
Si se compara con el modelo anterior, se verá que sólo se ha añadido el componente de la interacción de filas y columnas: γij
Este es un ejemplo esquemático del modelo:
Para optar a una maestría en una universidad extranjera se debe pasar por un período de entrenamiento y capacitación para luego presentarse el examen. Los programas de preparación son de tres tipos: Una sesión de repaso de 3 horas, un programa de un día y un curso de 10 semanas. Por otro lado, por lo general a este examen se presentan licenciados en Administración, Ingeniería y de Artes y Ciencia.
Según esto, un factor a ser estudiado es si la licenciatura de un postulante puede afectar a su calificación en la prueba. Un segundo factor a ser estudiado es si la forma de preparación que elija el postulante puede afectar su calificación en la prueba.
Cualquiera de los dos factores constituirán los tratamientos y el otro, los bloques.
La tabla del ANOVA será la misma excepto que el componente que antes generaba una variabilidad por bloques es generado por una nueva variable o un segundo factor, siendo los tratamientos el primero.
Las hipótesis y la tabla es la misma, de manera que pasaremos a resolver un ejemplo al respecto
Ejemplo 03
Una empresa de investigaciones prueba el rendimiento, en millas por galón, de tres marcas de gasolina. Como la gasolina tiene un rendimiento diferente en las diferentes marcas de automóviles, se seleccionaron 5 marcas de automóviles las que se consideraron como bloques en el experimento; es decir, cada marca se prueba con cada tipo de gasolina. Los resultados del experimento, en millas por galón, son los siguientes:
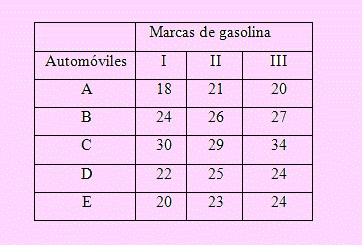
Formulación de la hipótesis:
Respecto a las marcas de gasolina:
Ho: El rendimiento medio en los tres tipos de gasolina es la misma
H1: Hay diferencia significativa en el rendimiento entre el tipo de gasolina
Respecto a la marca de automóvil:
Ho: La marca de automóvil no afecta en el rendimiento medio
H1: El rendimiento medio entre las marcas de automóvil es diferente.
Ingresando al Excel como el ejemplo anterior, tendremos los siguientes resultados:
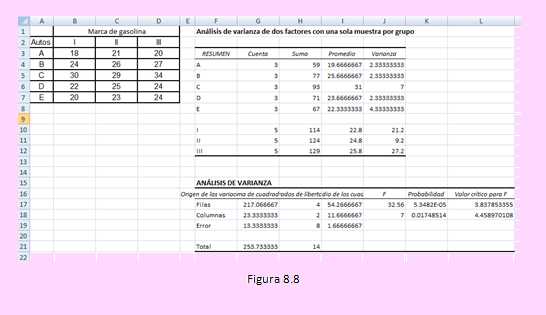
Criterio de decisión:
Como en ambos factores el estadístico Fc es mayor al valor crítico F a un nivel de significación del 5%, podemos afirmar que:
El rendimiento medio difiere entre las marcas de gasolina.
El rendimiento medio es diferente entre las marcas de automóviles.
Con Replicación
En este último caso, se consideran dos factores y por cada valor del factor por fila y por columna se disponen de muestras de tamaño mayor que uno. De allí que el modelo pretende explicar la variabilidad de los datos debido a la interacción entre los dos factores. El modelo es el siguiente:
xij = μ + αi +βj + γij + eijh, i = 1, 2,…, nj ; j = 1, 2,… k, i = 1, 2,…, l
En este modelo eijh representa la interacción entre los dos factores i y j y además el efecto con el aporta el h-ésimo elemento de la muestra. El siguiente esquema nos muestra el estado de una celda cualquiera.
| Factor j | |
| Factor i | n1 n2 ... nh |
Formulación de las hipótesis:
a) Debido a los tratamientos (Factor 1):
Ho: No hay diferencia en el efecto medio entre los tratamientos
H1: Hay alguna diferencia entre los efectos medios de algunos de ellos
b) Debido a los bloques o filas (Factor 2):
Ho: El efecto medio entre los bloques o factor 2 es la misma
H1: El efecto medio difiere entre los bloques
c) Debido a las interacciones entre el factor 1 y el factor 2:
Ho: No existe interacción en el efecto medio de tratamientos y bloques.
H1: Sí existe diferencia significativa entre ellos.
Tabla del ANOVA:
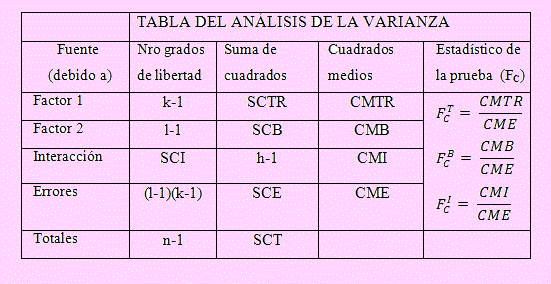
Lo nuevo en esta tabla: SCI = Suma de cuadrados de las interacciones
Grados de libertad de la varianza de las interacciones: h-1
CMI= SCI/(h-1)
Ejemplo 04
Tomando en cuenta el problema del acceso a la maestría por postulantes egresados con diferentes licenciaturas, tenemos los datos en el siguiente cuadro. Formule las hipótesis correspondientes y a partir de la tabla del ANOVA compruebe las hipótesis formuladas.
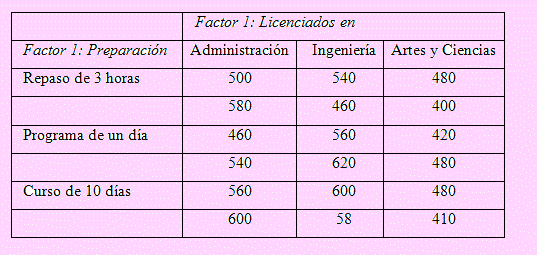
Los datos se ingresaron al Excel como se muestra en la siguiente imagen:
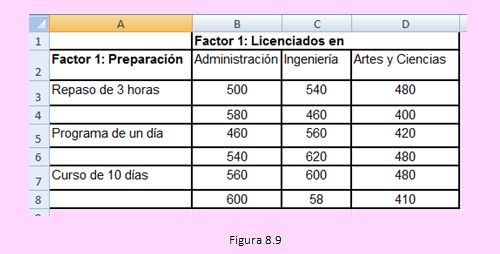
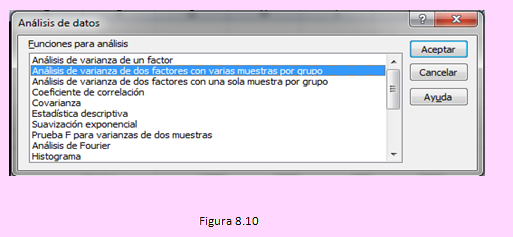
A continuación, usando la opción y llenando la ventana siguiente como se muestra,
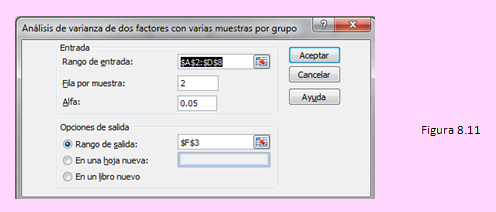
Se obtuvieron los siguientes resultados:
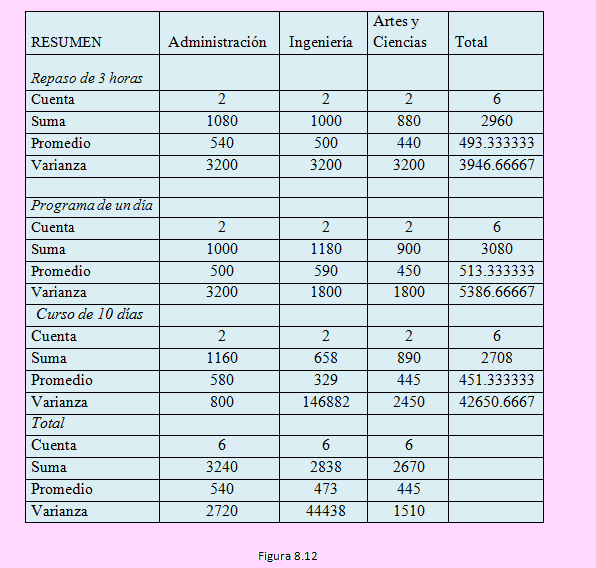
Y la tabla ANOVA es la siguiente:
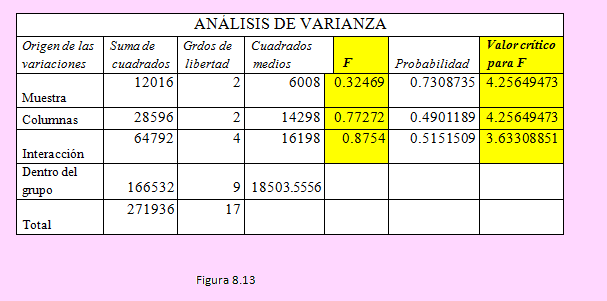
Observando la tabla podemos comprobar que, como los estadísticos de la prueba (FC) para cada pareja de hipótesis planteada es menor que el valor crítico correspondiente, no se rechaza la hipótesis nula, en consecuencia podemos afirmar:
a) El factor preparación para el examen de postulación no tiene efecto significativo sobre los postulantes.
b) El tipo de licenciatura de cada postulante no afecta significativamente en el acceso a la maestría
c) No hay interacción entre la forma cómo se preparen para la prueba ni el tipo de especialidad que tengan.



© Ilmer Condor Espinoza. Todos los derechos reservados.
Prohibida la reproducción por cualquier medio.
Publicación web autorizada a aulaClic.
Diciembre -2013.
Síguenos en: Facebook Sobre aulaClic Política de Cookies